[電子工作] シフトレジスタをAVRのSPIマスタで制御して7セグメントLEDを駆動する [電子工作]

元ネタ -> chan氏の LEDディスプレイを接続する
元ネタではソフトウェアで制御していますが、SPIマスタで制御出来ないかと思い
試してみました。
・コモン側(桁選択)のIC(164)を、74ACシリーズにしてトランジスタレスに簡略化。
※74AC164は1ピンで20mAくらい出せる。
今回は電流制限抵抗を1.8kΩとし、( (3.3V-2V)/1.8kΩ ) x 8 = 最大約6mAとしています。
超高輝度LEDを使っているので、1セグメントあたり0.7mAでも充分な明るさを得られています。
・MOSIピンを[74HC595のデータ入力ピン(14)]と[74AC164のデータ入力ピン(1,2)]に接続して
SPIマスタで制御
・MISOピンを[74HC595のラッチ(12)とイネーブル(13)]と[74AC164のクロック(8)]に接続
SPIマスタ中はAVR側が入力になってしまうので、プルダウンしておく。
・74AC164側にクロックを送る際はSPIをdisableにする。この時SCKピンとMISOピンの出力が
変化しないようにPORTB[4:5]の出力をSPIマスタの終了時の状態に合わせておく
SPIマスタを使うことで、データシフト -> ピン出力 -> クロック出力を最短2クロックで
できるので、ダイナミック駆動時のCPU負荷を軽減できるかな?
回路図とソースコードです。

[電子工作]マイコンで時間計測 - 最適なクロックはいくつ? [電子工作]
そこそこ精度の高い時間計測をしたいとします。
とりあえず、ふつーに手に入る水晶発振子の精度は±30ppmくらいでしょうか?
300秒で最大±0.01秒くらいですね。
分周+タイマ/カウンタをCTCモードで動かして、0.01秒単位で割込みをかけるには、
どの水晶を使えばより効率的でしょうか?
というわけで計算してみます。
(1) 12.288MHz
12288000 = 2^15 x 3 x 5^3 です。
タイマーのプリスケーラを/1024 (=2^10)とすると、タイマへの入力は12kHzとなり、
タイマのTOP値を120にすると100Hzとなり、0.01秒が作れます。
※8bitで足りることが重要
このクロックは、3.3V電源のAVRの安全動作範囲だったり、
44.1kHzのWAVをSDカードからreadしながら再生するのに充分な速度を出せたり、
TOP値を40と1/3にすると300Hz 約3.3mSで割込みがかけられて
4桁の7セグLEDをドライブしつつ、カウント3回で0.01秒を計時、をタイマー一個でできたりで、
なかなか重宝しそうなかんじなんですが、秋月に売ってないんですよね…
MP3デコーダ(VS1011e)を使うときにもこのクロックを使いたいので、
ぜひ取り扱って欲しいところです。
秋月にある水晶で使えそうなものを探してみます
(2) 9.216MHz
表面実装型のみですが…
9216000 = 2^13 x 3^2 x 5^3
タイマーのプリスケーラを/1024 (=2^10)とすると、タイマへの入力は9kHzとなり、
タイマのTOP値を90にすると100Hzとなり、0.01秒が作れます。
TOP値=30なら300Hz, 36なら250Hz。
一般的?なクロックではどうでしょう?
(3) 8MHz
8000000 = 2^9 x 5^6
100Hzを残すために2^2 x 5^2を残すとすると、
残念ながら2^7 = 128までしか分周できません。
AVRのプリスケーラでは128分周はなく、64分周(=125kHz)になり、
100Hzを作るにはTOP値=1250となってしまい8bitに収まりません。
が、TOP値=250 = 500Hzを5回カウントするという手があることはあります。
(4) 12MHz
12000000 = 2^8 x 3 x 5^6
8MHzはそこそこ使えるのですが、44.1KHzのWAVをSDカードから読みながら再生しようとすると
ちょ〜〜っと性能がたりません。
そこで12MHzを使おうとすると、、、
64分周で187.5kHz。100Hzを作るにはTOP値=1875です。
8MHz同様に500Hzを作ろうにも、まだTOP値=375。厳しいですねえ。
TOP値=75として8bitに収めると、割込み間隔=2500Hz= 0.4ms。
割込み間隔は4800クロックあるので、コードで25カウントしながら処理でも
よほどのことがなければタイマの取りこぼしは無さそうですが、どーでしょうね?
※16ビットタイマ/カウンタを使えばいいじゃん、、、というのもあるにはあるのですが、
Mega88系であれば16ビットタイマ1でCTCが使えるのですが、
Tiny861のタイマ0は16ビット動作にするとCTCが使えません。
OVF割込み(TOP=$FFFF)の度にTCNT値を書きなおすしか無いのですが、
分周器でTCNTをインクリメントするまで(=64clock弱)のうちに
書きなおす必要があり、面倒です。。。
※9.126MHzで44.1kHzのWAV再生が間に合うかは試せていません。
avrの動作電圧を5Vにできるのであれば、16.384MHz(=2^17 x 5^3)や、
19.6608MHz(=2^18 x 3 x 5^2)という選択肢もありそうです。
が、消費電力を考えると3.3V動作で12MHz台にしたいんですよねえ。
とりあえず、ふつーに手に入る水晶発振子の精度は±30ppmくらいでしょうか?
300秒で最大±0.01秒くらいですね。
分周+タイマ/カウンタをCTCモードで動かして、0.01秒単位で割込みをかけるには、
どの水晶を使えばより効率的でしょうか?
というわけで計算してみます。
(1) 12.288MHz
12288000 = 2^15 x 3 x 5^3 です。
タイマーのプリスケーラを/1024 (=2^10)とすると、タイマへの入力は12kHzとなり、
タイマのTOP値を120にすると100Hzとなり、0.01秒が作れます。
※8bitで足りることが重要
このクロックは、3.3V電源のAVRの安全動作範囲だったり、
44.1kHzのWAVをSDカードからreadしながら再生するのに充分な速度を出せたり、
TOP値を40と1/3にすると300Hz 約3.3mSで割込みがかけられて
4桁の7セグLEDをドライブしつつ、カウント3回で0.01秒を計時、をタイマー一個でできたりで、
なかなか重宝しそうなかんじなんですが、秋月に売ってないんですよね…
MP3デコーダ(VS1011e)を使うときにもこのクロックを使いたいので、
ぜひ取り扱って欲しいところです。
秋月にある水晶で使えそうなものを探してみます
(2) 9.216MHz
表面実装型のみですが…
9216000 = 2^13 x 3^2 x 5^3
タイマーのプリスケーラを/1024 (=2^10)とすると、タイマへの入力は9kHzとなり、
タイマのTOP値を90にすると100Hzとなり、0.01秒が作れます。
TOP値=30なら300Hz, 36なら250Hz。
一般的?なクロックではどうでしょう?
(3) 8MHz
8000000 = 2^9 x 5^6
100Hzを残すために2^2 x 5^2を残すとすると、
残念ながら2^7 = 128までしか分周できません。
AVRのプリスケーラでは128分周はなく、64分周(=125kHz)になり、
100Hzを作るにはTOP値=1250となってしまい8bitに収まりません。
が、TOP値=250 = 500Hzを5回カウントするという手があることはあります。
(4) 12MHz
12000000 = 2^8 x 3 x 5^6
8MHzはそこそこ使えるのですが、44.1KHzのWAVをSDカードから読みながら再生しようとすると
ちょ〜〜っと性能がたりません。
そこで12MHzを使おうとすると、、、
64分周で187.5kHz。100Hzを作るにはTOP値=1875です。
8MHz同様に500Hzを作ろうにも、まだTOP値=375。厳しいですねえ。
TOP値=75として8bitに収めると、割込み間隔=2500Hz= 0.4ms。
割込み間隔は4800クロックあるので、コードで25カウントしながら処理でも
よほどのことがなければタイマの取りこぼしは無さそうですが、どーでしょうね?
※16ビットタイマ/カウンタを使えばいいじゃん、、、というのもあるにはあるのですが、
Mega88系であれば16ビットタイマ1でCTCが使えるのですが、
Tiny861のタイマ0は16ビット動作にするとCTCが使えません。
OVF割込み(TOP=$FFFF)の度にTCNT値を書きなおすしか無いのですが、
分周器でTCNTをインクリメントするまで(=64clock弱)のうちに
書きなおす必要があり、面倒です。。。
※9.126MHzで44.1kHzのWAV再生が間に合うかは試せていません。
avrの動作電圧を5Vにできるのであれば、16.384MHz(=2^17 x 5^3)や、
19.6608MHz(=2^18 x 3 x 5^2)という選択肢もありそうです。
が、消費電力を考えると3.3V動作で12MHz台にしたいんですよねえ。
ATXMega始めました [電子工作]

今更感がないわけではないのですが、ATXMegaを使っていく方向で考えてみようかなと。
理由1:GPIOが多いAVRが欲しい。
28ピンAVR(Mega328とか)では、外部クリスタルを使うと使えるGPIOは20本。
たいていは足りるといえば足りるのですが、SPIやらUSARTやらをぶら下げていくと
足りなくなる時があったり。
XMega32D4は、外部クリスタルを使っても32本のGPIOが使えるのでウハウハw
理由2:安い&チップ単体で買える。
XMega32D4が秋月で250円(2016年4月現在)。
TQFP版のMega328より安いw
理由3:高解像度PWMがある。
メインクロックの4倍(HiRes+で8倍)の解像度でPWMを生成できる。
XMega以外ではtiny861aの高速PWMがあるけど、こっちは20ピンなのでGPIOの数がツライ。
※できたらXMegaAシリーズのDACが使いたいけれど、Aシリーズは共立で1700円とかする。ひええ。
理由4:AVRISPmkIIが使える。
わりと重要。
ARM系のATSAMDも興味があるけれどAtmel-ICEを買わないと?なのがなあとか。
(あと0.5mmピッチのハンダ付けはつらそう?とか)
理由5:Macの開発環境がそのままつかえそう?
わりと重要w
avr-gccとavrdudeで行けそうかなあと。
まだ試していませんが。
理由6:アセンブラの命令セットがこれまでもAVRと同じ
これまで作ってきたアセンブラ資産をできれば使いまわしたい。
対して困りポイント:
困り1:DIP版は無い。
44pinのDIPとか使いたくないですがw
0.8mmピッチなので、自分のようなブッキーでもまだ手半田できるのはありがたい。
変換ボードでもブレッドボードには挿せないので実験するときにちょっと困りますね。
これについては、ブレッド用の変換基板を作ってみようかなと。
困り2:日本語の資料が極端に少ない。
マニュアルもアプリケーションノートまで見ないと使い方がわかりづれえ。
アプリケーションノートのサンプルと、レジスタ定義のヘッダを見ながら実験してみないと?
ひとまず、変換ボードにPDIのコネクタを生やしてみたので、
単体で各ペリフェラルの動作を見ていきたいと思います。
※VCC-GND間にパスコン入れたほうがいいんでしょうけど、まあ実験ということで。
Atmelのarmコアマイコン [電子工作]
ATSAMD21を使ってみたいのだけれど、開発環境とかライタをどう用意すれば良いのだろう?
ACとDACが載っていてGPIOが豊富というのが、ちょうど欲しい機能に合致するんだけどなあ。
ACとDACが載っていてGPIOが豊富というのが、ちょうど欲しい機能に合致するんだけどなあ。
関数ポインタを辞めてstd::functionを使おう ついでにコールバックハンドラも [C++11]
「引数を取ってなんか処理して値を返す」的なものをなんでも格納できるstd::functionです。
実行結果:
ここまではたいして面白く無いですが、クラスのメンバ関数を格納できるとしたらどうでしょう?
実行結果:
注意は二点。
1. メンバ関数ポインタ(&C::func)に、インスタンスの参照(std::ref(obj))をバインドする
2. 引数分のプレースホルダ(std::placeholders::_1, std::placeholders::_2)をバインドする
1.は、メンバ関数の実行にはそのオブジェクトのインスタンスが必要ということ。
なので、呼び出し時にバインドしたインスタンスが存在しなければなりません。
2.は関数プログラミングで言うところの部分適用です。
バインドせずに後から指定する引数はこの書き方で明示が必要です。
応用として、コールバック用の仮想オブジェクトを用意していたところを、
std::functionを受け取るようにしてみます。
◯ふつうのコールバック
コールバック用のクラスを作ったり、実装したり、ポインタ渡しをしたり、
いろいろと面倒ですね。
一つのクラスで複数のコールバックを受けようとするとさらに面倒です。
(するのか?という疑問は別として)
◯std::functionを使って同じことをしてみる
またコールバックハンドラがクラスのメンバという必要もありません。
◯ラムダ関数にコールバックさせる
「std::functionでコールバック」はコールバックさせるハンドラの実装に柔軟性を
持たせられる利点があります。
がしかし、どの関数がコールバックされるものかが、わかりにくくなるという
デメリットがあるかもしれません。
その点、「普通の〜」はclass Xが'コールバックを実装している'ということを明示しているとも
言えるので、どちらを選ぶかは場面によって検討したほうが良いかも。
(柔軟性とわかりやすさは裏表?)
#include <iostream>
#include <functional>
int func(int a, int b)
{
return a + b;
}
int main()
{
// intを2つ受け取ってintを返す何かを格納するモノ
std::function<int(int,int)> f;
// フリー関数を格納
f = func;
// 呼んでみる -> フリー関数が呼ばれる
std::cout << f(1, 2) << std::endl;
return 0;
}
実行結果:
3
ここまではたいして面白く無いですが、クラスのメンバ関数を格納できるとしたらどうでしょう?
#include <iostream>
#include <functional>
class C {
private v_;
public:
explicit C(int v) : v_(v) {}
int func(int a, int b)
{
return a + b + v_;
}
};
int main()
{
// intを2つ受け取ってintを返す何かを格納するモノ
std::function<int(int,int)> f;
C obj(3);
// クラスCのインスタンスobjのメンバ関数を格納
f = std::bind(&C::func, std::ref(obj), std::placeholders::_1, std::placeholders::_2);
// 呼んでみる ※objの生存期間に注意
std::cout << f(1, 2) << std::endl;
return 0;
}
実行結果:
5
注意は二点。
1. メンバ関数ポインタ(&C::func)に、インスタンスの参照(std::ref(obj))をバインドする
2. 引数分のプレースホルダ(std::placeholders::_1, std::placeholders::_2)をバインドする
1.は、メンバ関数の実行にはそのオブジェクトのインスタンスが必要ということ。
なので、呼び出し時にバインドしたインスタンスが存在しなければなりません。
2.は関数プログラミングで言うところの部分適用です。
バインドせずに後から指定する引数はこの書き方で明示が必要です。
応用として、コールバック用の仮想オブジェクトを用意していたところを、
std::functionを受け取るようにしてみます。
◯ふつうのコールバック
#include <iostream>
#include <functional>
// コールバックハンドラ用のインタフェースクラス
class IX {
public:
virtual void callback(int a, int b) = 0;
};
// コールバックされる側の実装 -> IXを実装する
class X : public IX {
public:
virtual void callback(int a, int b) {
std::cout << "callback: " << (a+b) << std::endl;
}
};
// コールバック元
void cb(IX* hdl)
{
hdl->callback(1,2);
}
int main()
{
X o;
cb(&o);
return 0;
}
コールバック用のクラスを作ったり、実装したり、ポインタ渡しをしたり、
いろいろと面倒ですね。
一つのクラスで複数のコールバックを受けようとするとさらに面倒です。
(するのか?という疑問は別として)
◯std::functionを使って同じことをしてみる
class Y {
public:
void callback(int a, int b) {
std::cout << "callback: " << (a+b) << std::endl;
}
};
void cbf(std::function<void(int,int)> f)
{
f(1,2);
}
int main()
{
Y o;
cbf(std::bind(&Y::callback, std::ref(o), std::placeholders::_1, std::placeholders::_2));
return 0;
}
またコールバックハンドラがクラスのメンバという必要もありません。
◯ラムダ関数にコールバックさせる
void cbf(std::function<void(int,int)> f)
{
f(1,2);
}
int main()
{
cbf( [] (int a, int b) { std::cout << "lambda callback " << (a+b) << std::endl; });
}
「std::functionでコールバック」はコールバックさせるハンドラの実装に柔軟性を
持たせられる利点があります。
がしかし、どの関数がコールバックされるものかが、わかりにくくなるという
デメリットがあるかもしれません。
その点、「普通の〜」はclass Xが'コールバックを実装している'ということを明示しているとも
言えるので、どちらを選ぶかは場面によって検討したほうが良いかも。
(柔軟性とわかりやすさは裏表?)
[電子工作] ATTiny861Aのアナログコンパレータと、電力削減レジスタ [電子工作]
ATTiny861aの電力削減レジスタ(PRR)には、アナログコンパレータのビットがありません。
(アナログコンパレータの電源は、ADCSRAのACDビットに1を書いてオフにする)
電力削減レジスタのAD変換器のビットについて、データシートでは以下の説明になっています。
・Bit 0 – PRADC: Power Reduction ADC
Writing a logic one to this bit shuts down the ADC. The ADC must be disabled before shut down.
Also analog comparator needs this clock
アナログコンパレータだけ使いたい時でも、PRADCは0にしなくちゃいけない??
試しに、PRADC=1の状態で実際にアナログコンパレータを設定してみると、、、
動作します。
んーーー、どっちが正しいんでしょう?
※ADCの消費電流はけっこう大きいので、できればオフにしたいところ。
(アナログコンパレータの電源は、ADCSRAのACDビットに1を書いてオフにする)
電力削減レジスタのAD変換器のビットについて、データシートでは以下の説明になっています。
・Bit 0 – PRADC: Power Reduction ADC
Writing a logic one to this bit shuts down the ADC. The ADC must be disabled before shut down.
Also analog comparator needs this clock
アナログコンパレータだけ使いたい時でも、PRADCは0にしなくちゃいけない??
試しに、PRADC=1の状態で実際にアナログコンパレータを設定してみると、、、
動作します。
んーーー、どっちが正しいんでしょう?
※ADCの消費電流はけっこう大きいので、できればオフにしたいところ。
[電子工作] KiCadで設計した長穴のフットプリントをFusion PCB (Seeed studio)に注文してみる [電子工作]
こんな感じの部品用のスルーホールです。
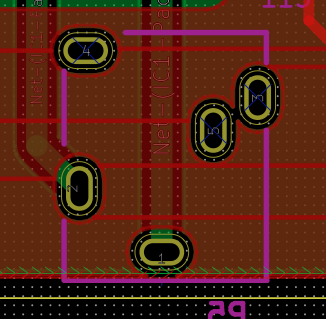
秋月で売っているこのパーツの取り付け用です。
(画像は裏から見た画になっています)
パッドの設定はこんな感じ
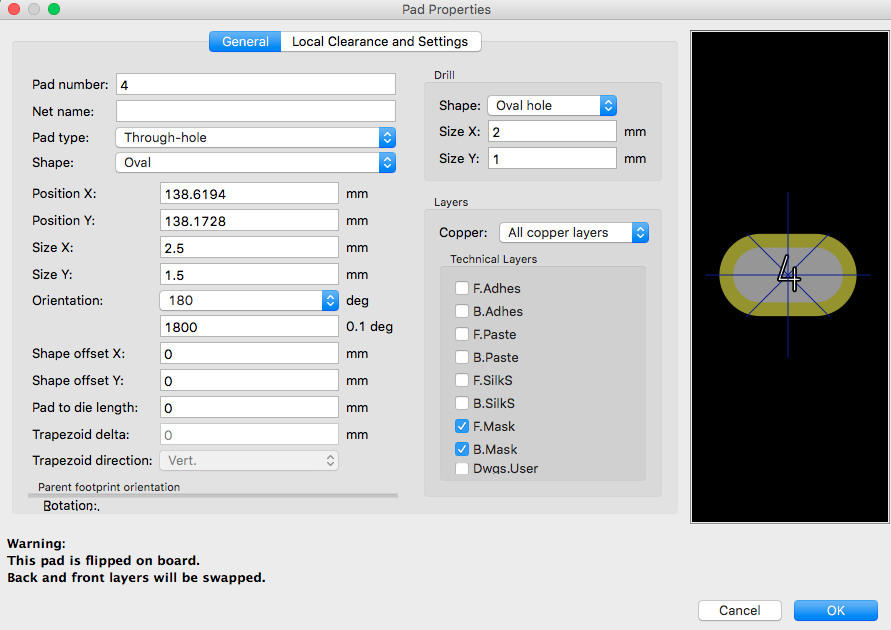
gerbvやFusion PCBのGerber確認画面では正しく表示されません…
が、ドリルファイルを見ると以下のように正しく?指定されているようでは有ります。
待つこと二週間ちょい。けっこう速く届きました。
きちんと長穴で仕上がっていました。

パーツもピッタリ!

ちょっとパッドが狭い気もするので、次に発注するときはパッドの設定を広げて見ようと思います。
秋月で売っているこのパーツの取り付け用です。
(画像は裏から見た画になっています)
パッドの設定はこんな感じ
gerbvやFusion PCBのGerber確認画面では正しく表示されません…
が、ドリルファイルを見ると以下のように正しく?指定されているようでは有ります。
G05 X122.609Y-138.173G85X121.609Y-138.173 G05 X126.865Y-149.43G85X125.865Y-149.43 G05 X129.242Y-142.13G85X129.242Y-143.13 G05 X131.72Y-140.297G85X131.72Y-141.297 G05 X138.271Y-145.373G85X138.271Y-146.373 G05 X139.119Y-138.173G85X138.119Y-138.173 G05 X143.375Y-149.43G85X142.375Y-149.43 G05 X145.752Y-142.13G85X145.752Y-143.13 G05 X148.23Y-140.297G85X148.23Y-141.297 G05
待つこと二週間ちょい。けっこう速く届きました。
きちんと長穴で仕上がっていました。

パーツもピッタリ!

ちょっとパッドが狭い気もするので、次に発注するときはパッドの設定を広げて見ようと思います。
[C++11][Boost] boost::asio::io_serviceを別スレッドでrunする [C++11]
久しぶりにやっていたらハマったのでメモ。
boost::asio::io_service::run()メソッドが引数の違いでオーバーロードされているので、
メンバ関数ポインタの型推論がメンドウなことになっています。
以降、
1.できそうで出来ないパターン
io_service::run()の型推論が出来ずにビルドエラーになってしまう。
2.メンバ関数の型を明示すればOKだが…
だがしかし、こんなこといちいち書いていられない。
(長いし読みづらい)
3.boost::bindでバインドすると、なぜか推論してくれる。
boost::bindとstd::bindが混在すると美しくないけれどそれでもよければ?
4.ちなみにstd::bindでバインドは?
もちろん、型を明示してstd::bindでバインドすればビルドが通りますが、
まったくもって意味が無いですね。
5.ところで、boost::threadは推論してくれるのでしょうか?
6.C++11ならラムダ式にしてしまうほうが簡単かも?
boost::asio::io_service::run()メソッドが引数の違いでオーバーロードされているので、
メンバ関数ポインタの型推論がメンドウなことになっています。
以降、
boost::asio::io_service io;とオブジェクトが宣言されているとします。
1.できそうで出来ないパターン
io_service::run()の型推論が出来ずにビルドエラーになってしまう。
// ビルドエラーになる std::thread th( &boost::asio::io_service::run, &io );
2.メンバ関数の型を明示すればOKだが…
だがしかし、こんなこといちいち書いていられない。
(長いし読みづらい)
// これは書きたくない
std::thread th(
(std::size_t
(boost::asio::io_service::*)())
(&boost::asio::io_service::run),
&io );
3.boost::bindでバインドすると、なぜか推論してくれる。
boost::bindとstd::bindが混在すると美しくないけれどそれでもよければ?
// boost::bindは推論できる
std::thread th(
boost::bind(&boost::asio::io_service::run,
&io) );
error_codeの引数有り版でもOK。すげえなboost::bind
// 引数有り版でも推論できる
boost::system::error_code ec;
std::thread th(
boost::bind(&boost::asio::io_service::run,
&io,
std::ref(ec)) ); 4.ちなみにstd::bindでバインドは?
// std::bidは? std::thread th( std::bind(&boost::asio::io_service::run, &io) );結果はNG! ううむむ。
もちろん、型を明示してstd::bindでバインドすればビルドが通りますが、
まったくもって意味が無いですね。
5.ところで、boost::threadは推論してくれるのでしょうか?
// boost::bidは? boost::thread th( &boost::asio::io_service::run, &io );これも結果はNG! boost::bindはできるのに〜
6.C++11ならラムダ式にしてしまうほうが簡単かも?
// 個人的にはこれが推し
std::thread th( [&io] { io.run(); } );
[C++11] std::threadを用いた並列処理のクラス化のスケルトン(即時実行型) [C++11]
C++でのthread実装については、ずっとboost::threadでやっていましたが、
徐々にC++11に置き換えていこうと思っています。
というわけで、自分がよく使う並列処理をクラス化するスケルトンを
std::threadで書き換えてみました。
まずは、遅延なしでインスタンスの生成と同時にスレッド処理を開始する版
worker.h
このサンプルでは、1秒毎に"Thread run!"の文字列を延々と出力し続ける処理を
スレッドで実行しています。
実際に使うときには、スレッド処理の部分を通信の非同期受信やキューからの
非同期取得などにします。
コメントでも記載していますが、std::threadのメンバ変数をメンバ変数の最後に定義することは、
とても重要です。
C++の仕様ではメンバ変数の初期化順はコードで定義している順、とされているので、
上の例で例えばstd::threadを一番最初に定義したりすると、スレッド中で参照している
メンバ変数の初期化が保証されなくなってしまうために、スレッドの起動時に落ちる
「場合がある」という謎の異常動作に悩まされる可能性があります。
(普通に動いてしまったりもするので、なお厄介です)
「while (true)」を「while (!abort_)」にしても良いような気もしますが、
abort_変数の参照がmutexロックのスコープ外になるとまずいのであえてこうしています。
(どうなんでしょうね?たぶんダメだと思いますが)
spurious wakeup対策をcondition_variableのwait_forメソッドで簡単に記載できるのが
良いですね。
昔々、boostのwaitメソッドで抜けてそのままコンテナにアクセスしに行くコードのせいで、
「時々異常終了する」謎の異常終了に悩まされたことがあったので…
abort_thread()メソッドを用意しすることで、確実にスレッドを終了&破棄できるように
しています。
デストラクタからも呼んでいるのでメイン側から明示的に呼ばなくても良いようにはしていますが、
明示的に呼んだほうが良いと思います。
スレッドとプロセスの生存期間が同じであればプロセスの破棄でついでにスレッドも破棄、
でもいいのですが(いいのかな?)、プロセスを殺さずにスレッドを止めたいことがあったので
安全に止められる仕組みを定番化しています。
それでも、複数のスレッドで協調動作するような実装の場合は、デッドロックせずに終了を
連鎖できるよう気を使いますね。
きちんと依存関係を整理して徹底しておかないと、タイミング依存でデッドロックしたり
開放済リソースにアクセスしてしまったりとこれまた謎の異常終了に悩まされる羽目になります。
スレッドは起動するよりも止めるほうがだいたい面倒が多いです。
このクラスの実行サンプルです。
main.cpp
スレッドを起動して、10秒待ってから終了を通知してします。
実行結果
非同期にスレッド側で通知を検知しているので、スレッド処理が実際に終了する前に
デストラクタが走っていることに注意してください。
つまり、スレッド処理で参照しているリソースを破棄する場合は、join待ちの後ろに
記載するよう注意が必要です。
次に、abort_thread()を明示的に呼ばない場合の実行結果も。
実行結果(2)
「notify abort event」が出力されるタイミングがデストラクタ内になっています。
徐々にC++11に置き換えていこうと思っています。
というわけで、自分がよく使う並列処理をクラス化するスケルトンを
std::threadで書き換えてみました。
まずは、遅延なしでインスタンスの生成と同時にスレッド処理を開始する版
worker.h
このサンプルでは、1秒毎に"Thread run!"の文字列を延々と出力し続ける処理を
スレッドで実行しています。
実際に使うときには、スレッド処理の部分を通信の非同期受信やキューからの
非同期取得などにします。
コメントでも記載していますが、std::threadのメンバ変数をメンバ変数の最後に定義することは、
とても重要です。
C++の仕様ではメンバ変数の初期化順はコードで定義している順、とされているので、
上の例で例えばstd::threadを一番最初に定義したりすると、スレッド中で参照している
メンバ変数の初期化が保証されなくなってしまうために、スレッドの起動時に落ちる
「場合がある」という謎の異常動作に悩まされる可能性があります。
(普通に動いてしまったりもするので、なお厄介です)
「while (true)」を「while (!abort_)」にしても良いような気もしますが、
abort_変数の参照がmutexロックのスコープ外になるとまずいのであえてこうしています。
(どうなんでしょうね?たぶんダメだと思いますが)
spurious wakeup対策をcondition_variableのwait_forメソッドで簡単に記載できるのが
良いですね。
昔々、boostのwaitメソッドで抜けてそのままコンテナにアクセスしに行くコードのせいで、
「時々異常終了する」謎の異常終了に悩まされたことがあったので…
abort_thread()メソッドを用意しすることで、確実にスレッドを終了&破棄できるように
しています。
デストラクタからも呼んでいるのでメイン側から明示的に呼ばなくても良いようにはしていますが、
明示的に呼んだほうが良いと思います。
スレッドとプロセスの生存期間が同じであればプロセスの破棄でついでにスレッドも破棄、
でもいいのですが(いいのかな?)、プロセスを殺さずにスレッドを止めたいことがあったので
安全に止められる仕組みを定番化しています。
それでも、複数のスレッドで協調動作するような実装の場合は、デッドロックせずに終了を
連鎖できるよう気を使いますね。
きちんと依存関係を整理して徹底しておかないと、タイミング依存でデッドロックしたり
開放済リソースにアクセスしてしまったりとこれまた謎の異常終了に悩まされる羽目になります。
スレッドは起動するよりも止めるほうがだいたい面倒が多いです。
このクラスの実行サンプルです。
main.cpp
スレッドを起動して、10秒待ってから終了を通知してします。
実行結果
+Worker::run Thread run! Thread run! Thread run! Thread run! Thread run! Thread run! Thread run! Thread run! Thread run! Thread run! notify abort event +Worker::~Worker aborted -Worker::run -Worker::~Worker
非同期にスレッド側で通知を検知しているので、スレッド処理が実際に終了する前に
デストラクタが走っていることに注意してください。
つまり、スレッド処理で参照しているリソースを破棄する場合は、join待ちの後ろに
記載するよう注意が必要です。
次に、abort_thread()を明示的に呼ばない場合の実行結果も。
実行結果(2)
+Worker::run Thread run! Thread run! Thread run! Thread run! Thread run! Thread run! Thread run! Thread run! Thread run! Thread run! +Worker::~Worker notify abort event aborted -Worker::run -Worker::~Worker
「notify abort event」が出力されるタイミングがデストラクタ内になっています。
タグ:C++11 std::thread
[電子工作] ATMEL AVRを喋らせてみようプロジェクト - ATtiny861A + ぷちFatFsでSDカードから再生 [電子工作]
再生するWAVの音質について、何を喋っているかわかればいいレベルであれば8KHz, 8bitでも
まあいいかなあという感じですが、せっかくなので44.1KHzも再生してみたくなります。
がしかし、ATMega328では8MHzクロックで8ビット分解能のPWMを生成する場合、
32KHzでしかパルスを生成できないので44.1KHzのサンプリングには間に合っていません。
このページによると、ATtiny24/45/85は250kHzの高速PWMが生成できるとあります。
データシートを調べてみると、マイコン内部で8MHz x 8倍のクロックをPLLで生成して
タイマ・カウンタのクロックに入力できるとのこと(8MHz x 8 / 256 = 250KHz)。
でも8ピンマイコンではSDカードとの接続とPWM出力でピンを使いきってしまうしなあと
思っていたところ、秋月でATtiny861Aなる石を見つけました。
これはtiny85の20ピン版と考えればよいでしょうか?
GPIOが15本(RESETを除く)あるので、SDカード(ピンx4)とPWM(1)で5本使っても
まだ10本もピンが残ります!
tiny85とtiny861Aの他に高速PWMを使えるAVRが見当たらなかったので、
8ピンオーディオプレーヤーをtiny861Aに移植してみました。

同じ系統の製品だし、ピンアサインだけ合わせればいけるだろうと軽く考えていましたが、
思わぬ罠にハマり丸一日悩むハメに。。。というわけで、情報を記事に起こしておきます。
tiny85 -> tiny861Aの移植チェックポイント
●FUSEビットは同じでOK
●SPIのSSの出力ピンは任意に選べる。
ピンアサインはaudiofunc.Sの先頭のB_CSをあわせる。
(PORTA側のピンにしたい場合は、ソースを検索してPORTB -> PORTAに変更)
●タイマのレジスタ構成が全く違うので、おなじ動作になるよう設定しなおす(main.c)
具体的には、こんな設定で動作しました。
※モノラルモードのみ。ステレオはTCCR1A=0b10100011のはずですが試していません※
ここで、TCCR1Aを設定した後でTCCR1Cに書くとPWMの出力設定が上書きされるので注意です。
(データシートの116ページ)
TCCR1AとTCCR1B以外はパワーオンのデフォルトのままでOKなので触らないほうが良いかも。
TOP値のOCR1Cが、パワーオン時に0xffになっているというのはちょっと便利ですね。
TIMER0側もCTCモードにするビットの設定が微妙に違う。
で、ここで、大きな罠がありました。
asmfunc.Sに定義しているコンペアマッチの割り込みベクタ名について、
ATtiny85はTIM0_COMPA_vectですが、
ATtiny861AはTIMER0_COMPA_vect
に変更が必要です。
avr-gccの定義値の違いでデータシートでは分からないし、コンパイルエラーにもならないので
気がつくのにえらい時間が掛かってしまいました。
<Tiny85のコンペアマッチ割込み処理の先頭>
<Tiny861Aのコンペアマッチ割り込み処理の先頭>
[ところで]
8ピンオーディオプレーヤーもですが、3.3V電源で16MHz動作はスペック外の動作?
(データシートによると10MHzより高い周波数で動作できるのは4.5V以上となっている)
まあ実際動作しているのでマージン内ということでしょうか。
※実際には、3.3Vでは12MHzまでが安全領域ということらしい。
[アンプ]
250KHzの高速PWM動作の出力をアンプ(TA7368の標準回路。電源6V)に突っ込むと
増幅し過ぎのようで音が割れまくりました。
けれど、マイコン -> LPF -> カップリングコンデンサ -> スピーカーではちょっと出力が寂しいかな。
ゲインを抑えたアンプを構成するか、ボリューム抵抗を入れると良いかも。
[SPI]
いま気がついたのですが、オリジナルの8ピンオーディオプレーヤーでは
データの出力(DOの制御)をわざわざコードを書いて行っています。
Tiny85ではOC1AがUSIのDOとぶつかっているので、ステレオ出力するときに
DOを別のピンに避ける為でしょうか。
Tiny861AではUSIで使うポートをPORTA側に変更すれば、
OC1AとOC1BをPWMで使ったままでSPIのデータ出力をマイコンのペリフェラルでできそう。
これは後でトライしてみます。
まあいいかなあという感じですが、せっかくなので44.1KHzも再生してみたくなります。
がしかし、ATMega328では8MHzクロックで8ビット分解能のPWMを生成する場合、
32KHzでしかパルスを生成できないので44.1KHzのサンプリングには間に合っていません。
このページによると、ATtiny24/45/85は250kHzの高速PWMが生成できるとあります。
データシートを調べてみると、マイコン内部で8MHz x 8倍のクロックをPLLで生成して
タイマ・カウンタのクロックに入力できるとのこと(8MHz x 8 / 256 = 250KHz)。
でも8ピンマイコンではSDカードとの接続とPWM出力でピンを使いきってしまうしなあと
思っていたところ、秋月でATtiny861Aなる石を見つけました。
これはtiny85の20ピン版と考えればよいでしょうか?
GPIOが15本(RESETを除く)あるので、SDカード(ピンx4)とPWM(1)で5本使っても
まだ10本もピンが残ります!
tiny85とtiny861Aの他に高速PWMを使えるAVRが見当たらなかったので、
8ピンオーディオプレーヤーをtiny861Aに移植してみました。
同じ系統の製品だし、ピンアサインだけ合わせればいけるだろうと軽く考えていましたが、
思わぬ罠にハマり丸一日悩むハメに。。。というわけで、情報を記事に起こしておきます。
tiny85 -> tiny861Aの移植チェックポイント
●FUSEビットは同じでOK
●SPIのSSの出力ピンは任意に選べる。
ピンアサインはaudiofunc.Sの先頭のB_CSをあわせる。
(PORTA側のピンにしたい場合は、ソースを検索してPORTB -> PORTAに変更)
●タイマのレジスタ構成が全く違うので、おなじ動作になるよう設定しなおす(main.c)
具体的には、こんな設定で動作しました。
TIMER1 : 高速PWM出力。DA変換のPWMを64MHzで出力する設定 TCCR1A = 0b00100001; /* Enable OC1B as PWM */ TCCR1B = 0b00000001; /* Start TC1 */
※モノラルモードのみ。ステレオはTCCR1A=0b10100011のはずですが試していません※
ここで、TCCR1Aを設定した後でTCCR1Cに書くとPWMの出力設定が上書きされるので注意です。
(データシートの116ページ)
TCCR1AとTCCR1B以外はパワーオンのデフォルトのままでOKなので触らないほうが良いかも。
TOP値のOCR1Cが、パワーオン時に0xffになっているというのはちょっと便利ですね。
TIMER0側もCTCモードにするビットの設定が微妙に違う。
TIMER0 : サンプリング期間毎にコンペアマッチで割込みを生成
TCCR0A = 0b00000001 (CTCモード)
TCCR0B = 0b00000010 (1/8)で、ここで、大きな罠がありました。
asmfunc.Sに定義しているコンペアマッチの割り込みベクタ名について、
ATtiny85はTIM0_COMPA_vectですが、
ATtiny861AはTIMER0_COMPA_vect
に変更が必要です。
avr-gccの定義値の違いでデータシートでは分からないし、コンパイルエラーにもならないので
気がつくのにえらい時間が掛かってしまいました。
<Tiny85のコンペアマッチ割込み処理の先頭>
;---------------------------------------------------------------------------; ; Audio sampling interrupt process ; ; ISR(TIM0_COMPA_vect); .global TIM0_COMPA_vect .func TIM0_COMPA_vect TIM0_COMPA_vect:
<Tiny861Aのコンペアマッチ割り込み処理の先頭>
;---------------------------------------------------------------------------; ; Audio sampling interrupt process ; ; ISR(TIMER0_COMPA_vect); .global TIMER0_COMPA_vect .func TIMER0_COMPA_vect TIMER0_COMPA_vect:
[ところで]
8ピンオーディオプレーヤーもですが、3.3V電源で16MHz動作はスペック外の動作?
(データシートによると10MHzより高い周波数で動作できるのは4.5V以上となっている)
まあ実際動作しているのでマージン内ということでしょうか。
※実際には、3.3Vでは12MHzまでが安全領域ということらしい。
[アンプ]
250KHzの高速PWM動作の出力をアンプ(TA7368の標準回路。電源6V)に突っ込むと
増幅し過ぎのようで音が割れまくりました。
けれど、マイコン -> LPF -> カップリングコンデンサ -> スピーカーではちょっと出力が寂しいかな。
ゲインを抑えたアンプを構成するか、ボリューム抵抗を入れると良いかも。
[SPI]
いま気がついたのですが、オリジナルの8ピンオーディオプレーヤーでは
データの出力(DOの制御)をわざわざコードを書いて行っています。
Tiny85ではOC1AがUSIのDOとぶつかっているので、ステレオ出力するときに
DOを別のピンに避ける為でしょうか。
Tiny861AではUSIで使うポートをPORTA側に変更すれば、
OC1AとOC1BをPWMで使ったままでSPIのデータ出力をマイコンのペリフェラルでできそう。
これは後でトライしてみます。
mick.neumann さん

-
nice! 3
記事 47
テーマ パソコン・インターネット
プロフィール
ブログを紹介する


